
Object detection을 수행하려면 객체가 존재할만한 지역의 후보군들을 추려내는 작업이 필요한데 이를 Region Proposal이라고 한다. 위 사진에서 2번과 같이 지역을 각각 나눠 하나씩 모델에 집어넣어 분류를 하는 방식을 취하게 되는데 2번의 과정이 region proposal이다. 대표적인 방법들에는 Sliding Window, Selective Search, RPN 등이 존재하는데 해당 방법들을 초기 방식이었던 sliding window와 selective search에 대해 알아보도록 하자.
① Sliding Window

sliding window은 초기의 localization 방식이다. 위 사진을 보면 초록 박스가 이미지 전체를 훑고 지나간 뒤 이미지 크기가 조절되며 해당 과정이 반복된다. 초록 박스를 window라고 하며 이 크기만큼의 이미지가 CNN에 입력되는 것이다. window의 위치가 이동할 때마다 그 크기만큼 crop된 이미지가 입력되며 window가 전체 이미지를 훑고 지나가면 region proposal이 전체 이미지를 커버하게 되는 것이다. 이렇게 되면 window가 전체 이미지를 훑으며 이미지 내 해당 크기로 검출할 수 있는 객체를 모두 찾아낼 수 있게 된다. 이후 window의 크기나 이미지의 사이즈를 바꿔가며 다양한 크기의 객체를 탐지할 수 있도록 한다.
알고리즘을 공부해봤던 사람은 바로 알아챘겠지만 이러한 방식은 완전탐색(Exhausted Search)의 개념을 그대로 가져다 쓴 방식이다. 검출하려는 객체가 전체 이미지 내에서 위치할 수 있는 모든 경우의 수를 그대로 때려넣은 구조라 당연하게도 계산량이 아주 많아진다. 기존 컴퓨터 비전에서는 선형분류기를 사용했기 때문에 연산량이 그나마 적어 쓸만 했지만 CNN과 같은 딥러닝 기반 classifier는 매우 많은 연산비용이 든다. 선형분류기는 wx+b 구조에서 파라미터가 2개 밖에 없지만 딥러닝 기반 CNN 구조에서는 필터의 사이즈, 개수, FC layer의 노드 수 만큼 파라미터가 증가하고 층이 깊어질수록 처리하는 행렬 연산도 많아지기 때문이다. 또한 하나의 객체를 찾기 위해 sliding window가 아주 많은 crop된 이미지를 CNN의 입력값으로 보내는 것도 연산량 증가에 한몫을 하게 된다. 하지만 이러한 문제점을 아래의 방식을 도입하며 어느정도 해결해 나간다.
Convolutional Implementation of Sliding Windows

우선 sliding window가 연산이 많이 걸리는 이유를 생각해 보면 다음과 같다.
1. CNN의 입력값의 크기는 고정
2. FC layer의 많은 연산량
1번의 이유는 FC layer 때문이라 할 수 있는데 위의 그림을 통해 알아보면 우선 FC layer는 400개의 노드들간의 연결이 파라미터로 개수가 고정돼있다. 이는 학습 과정에서 400x400개의 가중치를 학습하게 된다는 것을 의미한다. 이에 따라 FC layer 바로 전의 conv layer에서는 이미지를 1차원 배열로 펼쳤을 때의 크기가 400개가 되어야 하고 크기가 다르면 FC layer를 통과할 수 없는 것이다. 따라서 필터의 크기 등을 손보지 않는 한 초기 입력값의 크기는 14x14x3으로 고정돼 있어야 하고 각각의 crop된 이미지를 해당 크기로 resizing 하여 CNN의 입력값으로 넣게 된다.
2번에 대해서 위쪽 network의 첫번째 conv layer 파라미터를 계산해 보면 5x5x3x16=1200개이지만 FC layer의 파라미터는 400x400=160,000개다. FC에서는 모든 노드간의 연결이, conv layer에서는 필터의 크기, 개수만큼이 파라미터가 되기 때문에 이와 같은 차이가 발생하는 것이다.
이러한 문제의 해결책으로 제시된 것이 FC layer를 Convolutional layer로 바꾸는 것이다. 핵심부터 말하자면 이 방법으로
1)입력 사이즈의 제한이 사라졌고
2)중복된 연산과 여러 후보 region들을 한번에 처리할 수 있게 됐으며
3)학습에 필요한 연산량을 획기적으로 줄이게 되었다.

입력 사이즈에 제한이 생겼던 것은 FC layer에서는 노드간의 연결이 고정돼있었기 때문이었다. 하지만 conv layer에서는 필터의 크기와 개수가 고정돼 있으므로 어떤 크기의 입력값이 들어오든 필터 사이즈에 맞춰 연산값을 도출할 수 있다. 위 그림을 보면 맨 위의 구조가 14x14x3의 입력값을 고정으로 받는 conv net이고 중간은 FC layer를 conv layer로 바꾼 것으로 14x14x3 크기의 객체를 검출하는데에 있어 16x16x3이 입력값으로 들어 올 수 있는 것을 확인할 수 있다. 입력값으로 들어온 16x16x3에서는 14x14x3을 stride=2만큼 움직였을 때 총 4개(빨강, 초록, 주황, 보라)가 들어갈 수 있는 것을 확인할 수 있다. 즉 기존 FC layer에서 window size만큼 크롭된 이미지를 입력사이즈에 맞게 보정한 값을 4번에 걸쳐 받았던 것을 한번에 처리할 수 있게 된 것이다. 이는 FC에서는 1x1x400으로 크기가 고정되어 하나의 이미지만 처리할 수 있었지만 conv layer는 pooling layer 이후의 값에 필터가 stride=1만큼 이동해 연산을 진행하여 2x2x400의 값을(1x1x400이 4개나!!) 도출할 수 있기 때문이다. 이에따른 검출값은 좌측상단은 검출o, 나머지는 검출x 부분이라 볼 수 있다.
또한 빨강, 초록, 주황, 보라색의 14x14x3 사이즈 이미지들은 겹치는 부분이 대부분이다. 각각을 따로 계산하는 FC layer의 구조에서는 이 겹치는 부분을 4번이나 다시 연산을 해야했겠지만 conv layer로 바꾼 구조에서는 중복된 연산을 한번에 처리가 가능한 것이다. 입력 사이즈를 28x28x3로 더 키우면 연산의 효율성은 더욱 극대화된다. 4개가 아닌 64개의 window size에 맞춰 crop된 이미지를 한번에 처리할 수 있는 것과 동일해지기 때문이다! 이러한 이유로 convolutional implementation of sliding windows는 학습의 측면에서도 입력값에 대한 결과 도출의 측면에서도 상당한 연산상의 이득을 얻게 된다.

위 그림을 보면 더욱 잘 이해가 될 것이다. 입력 이미지의 크기가 28x28일 때 합성곱 신경망에 한번 통과시키는 것만으로 객체의 위치를 특정하게 될 수 있고 겹치는 부분들은 중복으로 연산되지 않아 계산이 빠르고 효율적으로 진행된다. 하지만 이러한 sliding window 어디까지나 크기가 정해져 있기 때문에 정확한 경계 상자를 그리는 것이 어렵다. Window 사이즈에 따라 object가 여러개 포함될 수도, 아예 포함되지 않을 수도 있다. 또한 FC layer을 CNN으로 바꾸면서 파라미터 수가 줄면서 복잡한 문제를 해결하기에는 더 어려워진 부분이 있다.
② Selective Search
exhausted search(=sliding window)는 window 크기를 조절해가며 이미지 내 모든 구역을 조사하기에는 연산량이 무지하게 많다. 따라서 많은 제약조건들이 필요했다. 또한 하나의 객체를 찾기 위해서 쓸데없는 지역을 너무 많이 조사하기 때문에 이에 따른 비효율성도 상당했다. 이러한 문제를 해결하기 위해 "객체가 위치할 만한 지역을 조사하자"는 발상으로 등장한 것이 Selective Search이다.

객체가 있을만한 지역을 조사하기 위해서는 일단 그러한 지역을 찾아내야 한다. Selective Search는 이를 segmentation을 활용해 구현해 낸다. Segmentation은 class independent object hypotheses를 생성할 수 있다는 장점이 있는데 이 말은 내가 검출하려는 class와 무관하게 객체 후보군이 생성된다는 것이다. 이렇게 되면 하나의 객체만 포착되는 것이 아니라 다른 객체들, 심지어 배경까지 포착해낼 수 있다. 위 사진의 (a)를 보면 selective search는 사람 뿐만 아니라 양들, 초원, 하늘까지도 모두 잡아내고 있다.
exhausted search도 한 가지 이점이 있는데 어떤 크기의 객체든 이미지 내에서 찾아낼 수 있다는 점이다. 뭐 완전탐색방식이니 당연한 부분이다. 그리고 이러한 이점을 selective search에서도 다른 방식을 통해 보존해 간다. 결국 selective search는 한마디로 exhausted search와 segmentation의 장점을 합친 것이라 할 수 있다. 그렇다면 sliding window 방식을 사용하지 않고 완전탐색의 이점을 어떻게 유지할 수 있는걸까?
Hierarchical Grouping Algorithm
그 해답은 hierarchical grouping algorithm에 있다. Selective Search에서는 이 알고리즘을 활용해 모든 scale의 객체를 포착해 낸다. 이는 작은 구역을 조금씩 합쳐나가며 더 큰 scale의 구역을 만들고 그렇게 모든 scale을 커버할 수 있도록(Capture All Scales) 하는 알고리즘이다. 아래는 hierarchical grouping algorithm의 구체적인 동작 과정이다.

작동과정은 다음과 같다.
1. 이미지 입력
2. segmentation을 사용해 초기구역 R 획득, 구역 간 유사도 집합 S는 공집합
*초기 구혁 획득할 때는 "Efficient Graph-Based Image Segmentation(2004)"이라는 논문(=[13])에서 제시된 방법을 사용
3. 각 구역간의 유사도를 구해 S에 추가
*n개의 구역이 있으면 총 nC2개의 구역 쌍에 대한 유사도가 나올 것
4. 유사도가 가장 높은 두 구역을 합쳐 r_t라 정의
*r_i와 r_j의 유사도가 가장 높다면 r_t = r_i U r_j
5. r_i와 다른 모든 구역의 유사도, r_j와 다른 모든 구역의 유사도를 S에서 제외
6. r_t와 나머지 구역들의 유사도 집합을 구해 S에 추가 & r_t를 R에 추가
7. 이를 S가 공집합이 될 때까지 반복한 뒤 R에 남아있는 지역들이 selective search의 결과 L!
*이때 L은 초기 지역+그리디를 통해 합친 지역들이다.
간단히 말하자면 입력된 이미지에서 segmentation을 활용해 초기구역을 나누고 가장 유사한 두 구역을 합쳐나가면서 더 큰 scale을 커버할 수 있는 region들을 만들어 최종적으로 전체 이미지가 하나의 region이 될 때 까지 반복하는 과정이라 할 수 있다. sliding window가 완전탐색 방식이었다면 selective search는 그리디(greedy) 방식을 취하는 것이다.
이 방식이 효과적으로 작동하려면 유사도를 빨리 계산해야 되는데 이를 위해서는 유사도가 계층적으로 전달될 수 있는 특징에 근거해야 한다. 즉 r_i와 r_j를 합쳐 r_t를 만들 때 r_t의 특징은 image pixel에 직접 접근할 필요 없이 이전에 계산되었던 r_i와 r_j의 특징을 기반으로 계산되어야 한다는 것이다. 아마 저게 뭔소린지 싶을 텐데 이는 selective search에서 제시하는 Diversification Strategies에서 구체적으로 알 수 있다.
Diversification Strategies
이는 한가지 특징만을 고려해 객체를 탐지하는 것이 아니라 여러 특징들을 종합적으로 고려하여 객체를 탐지하고자 하는 전략이다. 아래 사진에서 texture이라는 특징 하나만을 고려해 TV와 여성을 구분하고자 하면 어려울 수도 있다. 하지만 selective search에서는 추가적인 다른 특징들을 종합적으로 고려하여 둘을 구분해낼 수 있는 것이다. 세부적으로는 complementary color spaces, complementary similarity measures, complementary starting regions 세 가지 전략이 있는데 이를 모두 사용해 diversification strategies를 효과적으로 구현한다.

Complementary Color Spaces

이는 서로 다른 특징 갖는 다양한 color space(색공간)들을 사용하는 전략이다. 위 표를 보면 색공간 별로 Light Intensity, Shadows/shading, Highlights의 부분에서 각기 다른 특징을 지닌다. +는 해당 특성이 invariant 하다는 것, -는 variant 하다는 것을 의미하고 1/3은 3개의 colour channels 중 1개의 channel만 variant 하다는 것이다. HSV의 Highlights부분을 예로들면 H, S, V 3개의 colour channel 중 H 1개의 채널만 + 성질을 띄기 때문에 1/3인 것이다. 이같이 색공간 별로 특징이 다르기 때문에 이를 종합적으로 활용하면 더욱 정확한 bounding-box를 그릴 수 있게 되는 것이다.(하지만 시간은 좀 더 오래 걸린다.)
Complementary Similarity Measures

이는 유사도의 계산과 관련된 부분이다. 최종 유사도는 colour, texture, size, fill 유사도 4가지의 합으로 계산된다. 이때 유사도의 값들은 계산 편의를 위해 [0, 1] 범위로 조정된다. 우선 colour 유사도부터 알아보자.
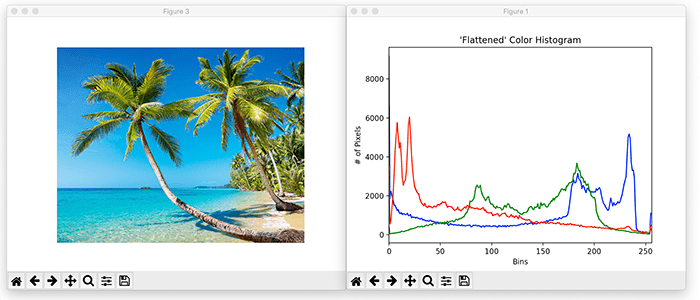
<colour 유사도>
두 region의 유사도를 계산을 이해하기 위해서는 우선 color histogram에 대한 이해가 필요하다. 일반적으로 색은 RGB로 표현되는데 R, G, B 각각이 밝기에 따라 0~255 사이의 값을 가지고 합쳐져서 색이 표현되는 것이다.(0 가장 어두움, 255 가장 밝음) 이때 색은 픽셀 단위로 표현된다. 위 사진을 보면 픽셀이 가지는 밝기(gray scale)를 x축으로, 해당 밝기를 가지는 pixel의 개수를 y축으로 R, G, B를 각각 표현한 그래프가 나타나는데 이를 히스토그램으로 표현한 것이 color histogram이다.


selective search의 similarity measures에서 colour 유사도를 구할 때는 255 bins를 사용하는 것이 아니라 25 bins를 사용한다. colour channel별로 25개의 bins를 가지기 때문에 만약 RGB를 사용한다고 하면 n=75인 colour histogram을 가지게 된다. 만약 r_i와 r_j의 유사도를 구한다면 C_i와 C_j를 각각 구해야 한다. 그 다음 이 둘의 histogram intersection을 구하면 colour 유사도가 나온다. histogram intersection은 수식을 보면 어려울 수 있으나 아래를 보면 이해하기 쉽다.

위 그래프를 각각 75개의 bins를 가진 colour histogram이고 x축이 정규화 돼 있는 것이라 생각해 보자. histogram intersection은 말그대로 두 히스토그램이 교차하는 지점을 의미한다. 이때 교차하는 지점은 두 히스토그램의 x값이 같은 지점에서 y값이 더 작은 것을 의미한다. 그래서 수식이 min( , )을 다 더하는 구조가 되는 것이다.
오케이. 이제 유사도를 구하는 방식은 완전히 이해가 될 것이다. 그렇다면 아~까전에 유사도 계산 속도 향상을 위해 r_i와 r_j의 특징을 기반으로 r_t의 특징을 구한다는 것은 그래서 도대체 무슨 의미인 것일까?
colour 부분에서 특징은 colour histogram을 의미한다. 따라서 위 말은 r_i와 r_j의 colour histogram을 바탕으로 r_t의 colour histogram을 구한다는 것을 의미한다. 이는 아래의 수식을 통해 구할 수 있다.

처음에 유사도는 계산 편의를 위해 [0, 1]의 범위로 맞춰준다고 하였기 때문에 colour histogram의 y값 즉 해당 gray에서의 픽셀 수는 전체 픽셀에서의 비율로 조정된 상태이다. 따라서 위 수식에서는 size(r_i), size(r_j)와 같은 값들이 곱해지고 그 합으로 나눠주는 것이다. 의미적으로 C_t = C_i+C_j이라 봐도 무방하다. 즉 r_i와 r_j가 합쳐져서 만들어진 새로운 구역 r_t의 colour histogram은 r_i와 r_j의 colour histogram을 단순히 합하는 것 만으로 구할 수 있다는 것이다.
<texture 유사도>


texture 유사도를 산출하는 메커니즘도 colour와 동일하다. 똑같히 histogram을 구하고 histogram intersection을 구함으로써 유사도를 산출하는 방식이다. 하지만 colour 유사도에서는 단순하게 colour histogram을 썼지만 texture 유사도에서는 fast SIFT-like measurements를 활용해 texture histogram을 구성한다. texture histogram이 어떻게 구성되는지 자세히 알기 위해서는 "Exploring features in a bayesian framework for material recognition(2010)"이라는 논문을 참조해야 하지만 내용이 너무 비대해지므로 여기선 생략하도록 하겠다. 대충 CNN이 대상의 특징을 추출하는 것처럼 texture 특성을 추출하는 방법이라고만 알아놓자. 자세한 내용이 궁금하면 아래 링크를 통해 한번 참조해 보시길!
https://www-bcs.mit.edu/pub_pdfs/maltRecogCVPR10.pdf
<size 유사도>

size 유사도는 작은 지역들이 먼저 합쳐지도록 유도한다. 작은 지역들부터 병합해 나가는 것은 모든 scale의 객체들을 탐지할 수 있도록 하기 위함이다. 사실상 sliding window의 이점이 hierarchical grouping algorithm 내의 size 유사도를 통해 구현되는 것이다. 위 식을 보면 1에서 두 지역이 전체 이미지에서 차지하는 비율을 빼준다. 두 지역의 크기가 작을수록 size 유사도의 크기는 증가해 전체 유사도의 크기는 증가하게 된다. hierarchical grouping algorithm은 유사도가 높은 지역들부터 합쳐나가므로 size 유사도를 통해 작은 지역들이 먼저 합쳐지도록 유도된다고 볼 수 있는 것이다.
<fill 유사도>

fill 유사도는 가까이 있는 regions 부터 합쳐지도록 유도한다. 만약 멀리 떨어져 있는 두 region이 합쳐지면 각 region들과는 관계없는 다른 region이 포함되기 때문에 꼭 필요한 부분이라 할 수 있다. BB_ij는 r_i와 r_j를 tight하게 감싸는 bounding-box이다. 위 수식의 분모는 bounding-box 내 r_i와 r_j와는 관련없는 지역이라 할 수 있는데 r_i와 r_j가 가까이 있을수록 그 값은 작아진다. 이렇게 되면 fill 유사도는 높아지고 hierarchical grouping algorithm에 따라서 더 빨리 합쳐지게 되는 것이다.
이렇게 각각 구해진 유사도 측정치들을 다 더하면 최종 유사도가 산출된다. a는 0 or 1의 값으로 해당 측정치를 사용 유무를 정하는 값이다. 저렇게 a를 추가로 달아놓은 이유는 특별한건 없고 그냥 다양한 조합으로 실험해보기 위함이다.
Complementary Starting Regions
이는 초기 regions을 다양화하며 그 질을 높이는 방식이다. 여기서는 새로운 방식을 제시하지는 않고 "Efficient Graph-Based Image Segmentation[13]" 에서 제시된 oversegmetation 방식을 그대로 차용한다.
평가 방식


selective search의 논문을 보면 위와 같은 평가지표를 통해 성능을 측정한다. ABO는 한 클래스에 대한 성능이라고 할 수 있는데 G^c는 c라는 클래스의 ground truth이고 g_i^c는 이미지 내 c라는 클래스에 해당하는 객체가 여러개 있을 때 각각의 ground truth를 나타낸다(사람을 검출하려 할 때 이미지 내 사람이 여러명인 경우). maxOverlap(g_i^c, l_j)는 g_i^c와 selective search로 생성된 여러 locations인 L이 겹치는 부분중 가장 큰 부분을 나타낸다. c라는 클래스에 해당하는 객체가 여러개 있을 때 각각의 ground truth의 maxOverlap을 다 더한 후 평균을 낸 것을 ABO라고 할 수 있겠다. 클래스가 1개가 아닌 여러개라면 각 클래스에 해당하는 ABO를 모두 더해준 후 평균을 낸 MABO를 통해 성능을 측정할 수 있다.
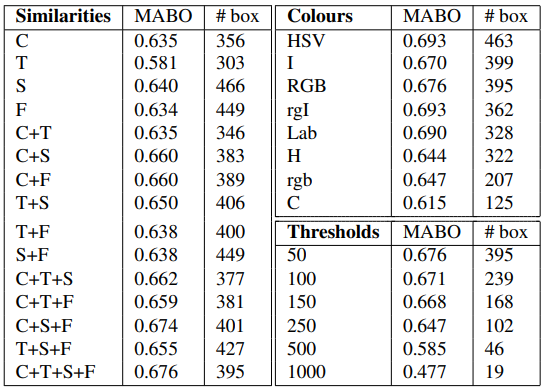

이전에 최종 유사도를 계산할 때 각각의 유사도에 a가 덧붙여졌는데 이는 위쪽 표와 같이 다양한 조합을 통해 실험하기 위해 붙은 것이다. selective search는 위와 같이 유사도 조합, color space, 초기지역을 낼 때의 변수인 thtresholds를 다양하게 조합하며 성능을 측정한다. 아래쪽 표는 greedy search를 통해 각각 단일 전략, 속도 우선 전략, 성능 우선 전략에서 가장 좋은 조합을 찾아낸 것이다. 성능 우선 전략을 보면 color space 5개, 특징조합 4개, thresholds 4개로 총 80개의 전략이 도출되고 각 전략에 따른 locations 중 중복된 것은 하나를 제거한 뒤 bounding box 생성에 활용한다.
이러한 방식을 거쳐 생성된 selective search의 bounding-box는 무지하게 많고 또 ground-truth와 차이가 꽤나 있다. 따라서 여러 박스 중 최선의 박스를 하나 선택하고 이를 ground-truth에 더 가까이 이동시켜 주는 작업이 필요한데 이에 각각 NMS(Non-Max Suppresion)과 Bounding-box regression이 사용된다. NMS를 계산하는데는 일반적으로 IoU(Intersection of Union)라는 개념도 필요하다. 이 부분까지 추후에 다른 글로 다뤄보도록 하겠다.
<참고자료>
17. Recent advances in deep learning for object detection
### $\equiv$ CONTENTS 1. Introduction 2. Problem Settings 3. Detection Components 3.1. Detection …
wikidocs.net
2) Localization
## Sliding window object detection Sliding window는 (1)에서 간략하게 소개가 되었었는데요, 모든 **location**에 대해 **sc…
wikidocs.net
https://www.youtube.com/watch?v=XdsmlBGOK-k&list=PL_IHmaMAvkVxdDOBRg2CbcJBq9SY7ZUvs&index=4
https://velog.io/@pabiya/Selective-Search-for-Object-Recognition
Selective Search for Object Recognition
오늘 리뷰할 논문은 R-CNN에서 region proposal을 하는 원천 기술인 selective search 알고리즘에 대한 논문이다. R-CNN 논문을 읽고 궁금해져서 리뷰하게 되었다.이 논문의 목표는 object recognition에 이용할
velog.io
selective search 논문
http://www.huppelen.nl/publications/selectiveSearchDraft.pd
'Deep Learning > Computer Vision' 카테고리의 다른 글
| Computer Vision의 다양한 과제: Image Classification, Localization, Object Detection, Segmentation (11) | 2024.05.05 |
|---|