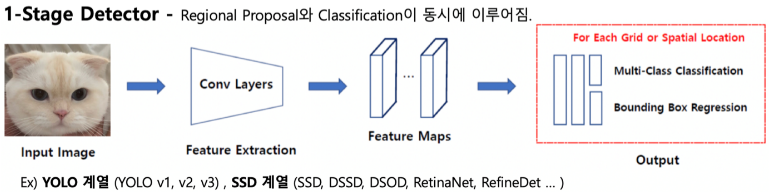
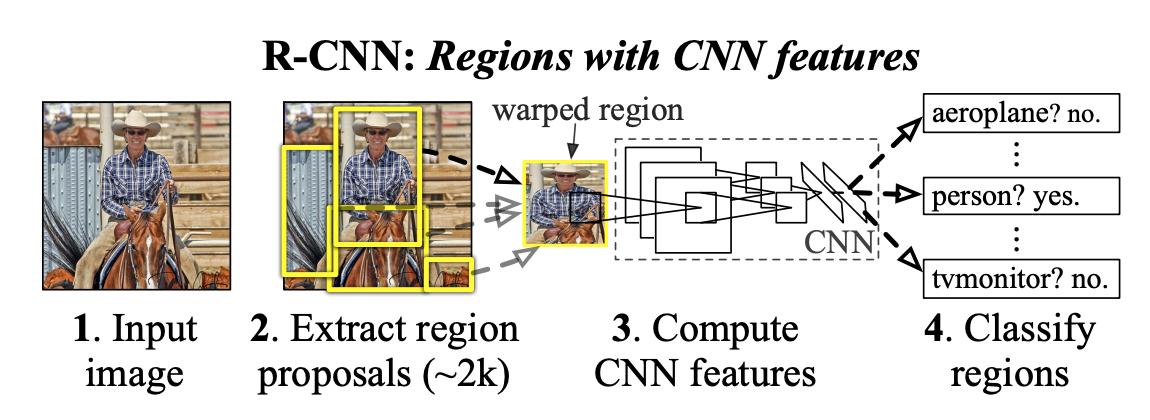
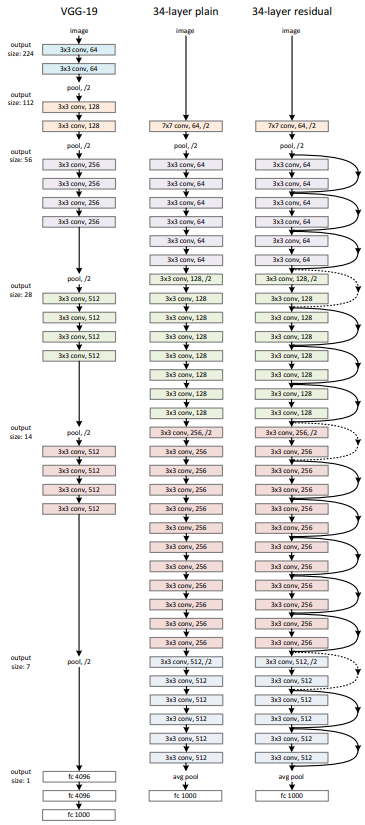
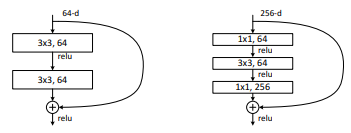
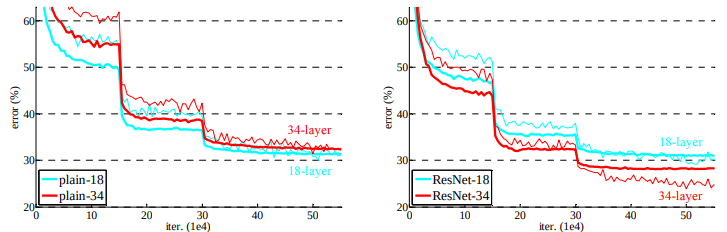
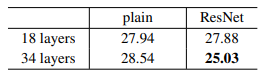
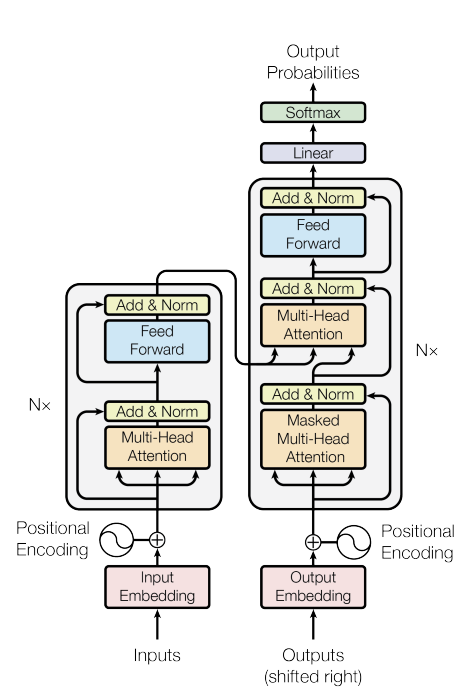
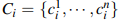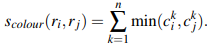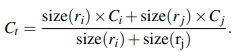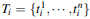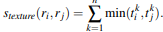Transformer는 2017년 구글 브레인의 'Attention is all you need'이라는 논문을 통해 등장한 모델로 처음에는 번역 성능을 높이기 위한 목적으로 고안되었으나 현재 NLP와 Vision 분야 모두에서 활발히 활용되고 있다. Transformer는 attention 메커니즘을 근간으로 한 모델으로 기존에는 attention과 RNN이 결합되어 사용되었지만 Transformer는 RNN 없이 오직 attention만 사용하여 학습 속도는 높이면서도 성능을 더욱 높일 수 있었다. 오직 attention만을 사용하기 위해서는 self-attention 방식을 적용해야 했는데 Transformer 등장 이후 이러한 self-attention 방식을 사용하는 것이 주류를 이루게 되었다. 그렇다면 Transformer가 어떤 구조를 가지고 어떻게 동작하는지 한번 파헤쳐보도록 하겠다.
1. Attention
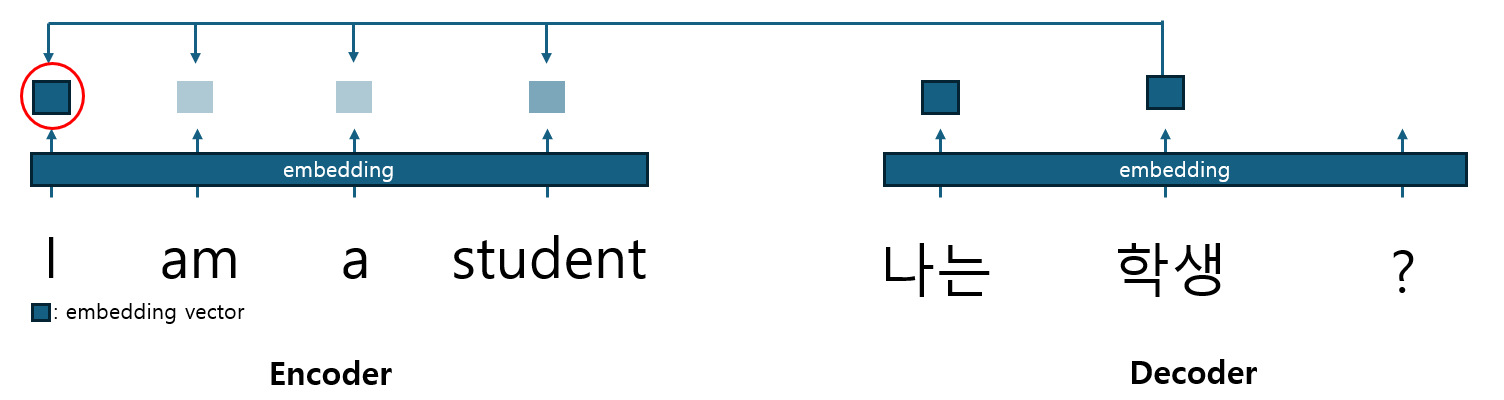
Transformer를 이해하려면 우선 어텐션 메커니즘을 이해해야 한다. 어텐션이 무슨 뜻인가? 바로 주의를 기울인다는 뜻이다. 바로 이 직역한 바 자체에 어텐션의 핵심이 담겨있다. 어텐션 메커니즘은 출력 단어를 예측하는 매 시점 마다 입력 문장을 참고하는 데 입력문장의 각 단어 중 현재 예측하려는 단어와 연관성이 높은 부분에 더 주의를 기울여(attention) 예측을 하는 방식이다. 그림1은 영어 문장을 한국어로 번역하는 과정이다. 번역기가 '나는' 다음 단어를 예측할 때 '나는'이라는 단어와 'I', 'am', 'a', 'student' 각각의 단어가 서로 유사한 정도를 반영하여 다음 정보를 예측한다는 것이다. am, a 보다는 상대적으로 I, student의 embedding vector에 대한 정보가 더 많이 반영되어 다음 단어를 예측하게 된다는 것이다.
1.1 Scaled Dot-Product Attention


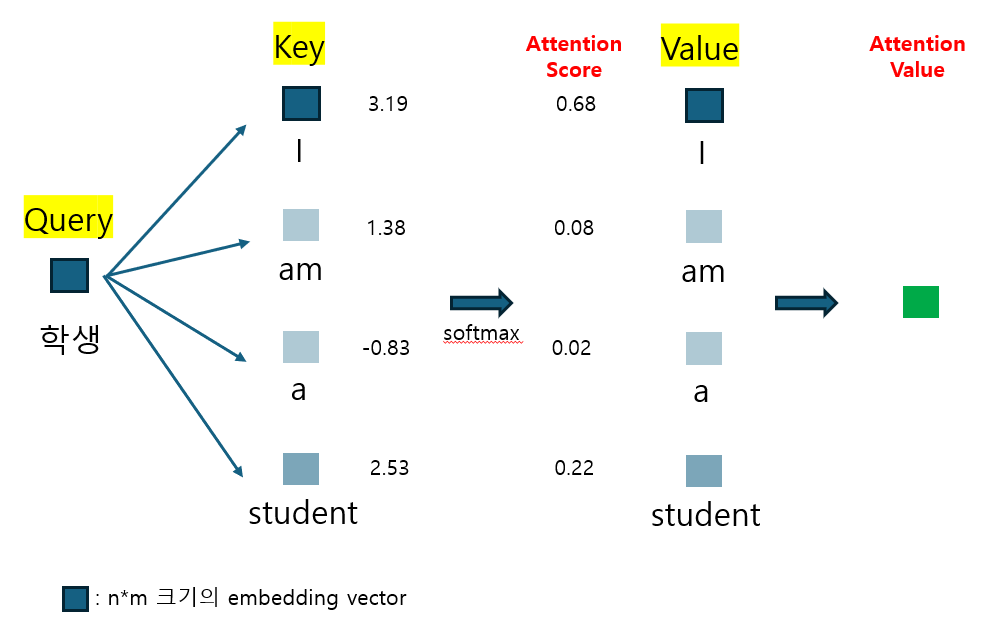
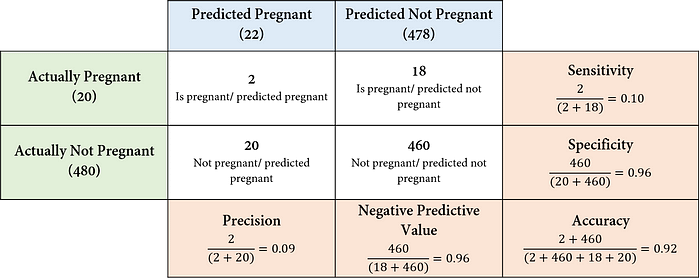
그렇다면 이 과정이 구체적으로 어떻게 진행되는지 살펴보자. 우선 어텐션을 수행하기 이전에 Query, Key, Value 값들이 필요하다. 이는 그림2에서 확인할 수 있는 바와 같이 Q = W_q*X, K = W_k*X, V = W_v*X으로 구해진다. 그리고 나서 '나는' 다음 단어를 예측할 때는 우선 '학생'이라는 Query값과 'I', 'am', 'a', 'student' 각각의 Key값의 내적값들을 구하고 여기에 softmax 함수를 적용해 가중치인 Attention score를 산출한다. 이후 Value값을 다시 곱하여 Attention value를 구한 뒤 이를 다음 글자를 예측하는 데에 활용하는 것이다. 즉 attention score는 가중치가 되고 attention value는 value값들의 가중합으로 볼 수 있다. 이러한 과정을 담은 식이 그림2의 식이다. 이렇게 되면 Attention value는 입력문장인 'I am a student'에서 '학생'과 다른 단어들과의 유사도가 혼합된 정보를 담고있는 채로, 특히 '학생'과 더 유사한 글자에 대한 정보를 더 많이 담고 있는 채로 다음 글자를 예측하게 된다. 이때 '학생'의 Query의 크기를 1x2라 했을 때 K의 전치는 2X4로 attention socre의 크기는 1x4가 되고 vaule의 크기는 4x2이므로 attention value는 1x2의 크기를 가지게 된다.
그림2의 식에서 d_k는 keys의 차원을 나타낸다. 입력 문장이 길어져 keys의 차원이 크게 증가하게 되면 Q*K^T의 값은 크게 증가하여 softmax 함수 상에서 기울기가 거의 0에 가까워지는 부분의 값을 갖게될 것이다. 이에 따라 기울기가 매우 작아 역전파 과정에서 학습이 제대로 되지 않을 수 있기 때문에 루트(d_k) 만큼의 값으로 scaling을 해주는 것이다.
1.2 Self Attention
지금까지 본 내용들은 Decoder에서 다음 단어 예측을 위해 Encoder를 참조(attention)하는 방식이었다. 하지만 self attention은 encoder, decoder 각각 그 내부에서 각 단어들이 다른 단어를 참조하는 방식이다. 즉 encoder, decoder가 attention을 자기 자신에게 취하는 방식인 것이다. 다음 두 문장을 보면 왜 self attention 방식을 취하는지 이해하기 쉽다.
① The animal didn't cross the street because it was too tired.
② The animal didn't cross the street because it was too wide.
다음 두 문장을 보면 it이 가리키는 바가 각각 animal, street로 다르다는 것을 알 수 있다. 문장을 제대로 번역하기 위해서는 문장 내 혹은 문장간 문맥을 제대로 파악하는 것이 중요하다. Transformer 모델에서는 self attention을 통해 이러한 문맥 파악 작업을 할 수 있는 것이다. 문맥을 파악하는 작업은 번역의 대상이 되는 문장에서도, 순차적으로 번역을 해나가는 과정 속에서도 모두 중요하기 때문에 self attention은 encoder와 decoder에 모두 활용이 된다.
* RNN과 결합된 attention 모델에서는 decoder가 encoder를 참조하는 과정에서 attention이 활용되었고 문맥을 파악하는 작업은 RNN이 담당했다. 하지만 self attention 구조의 도입으로 RNN을 attention으로 완전히 대체할 수 있게 되면서 순수 attention 혈통을 가진 Transformer가 탄생하게 된다...!
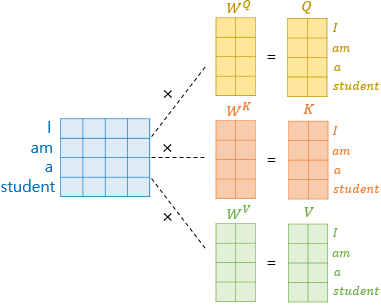
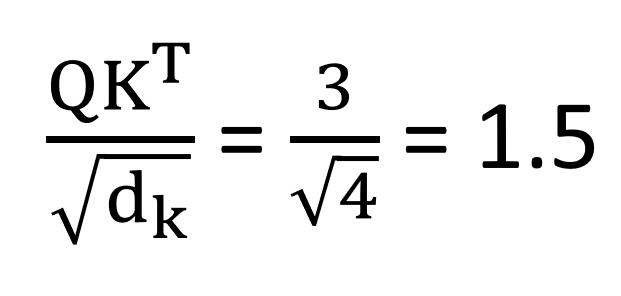

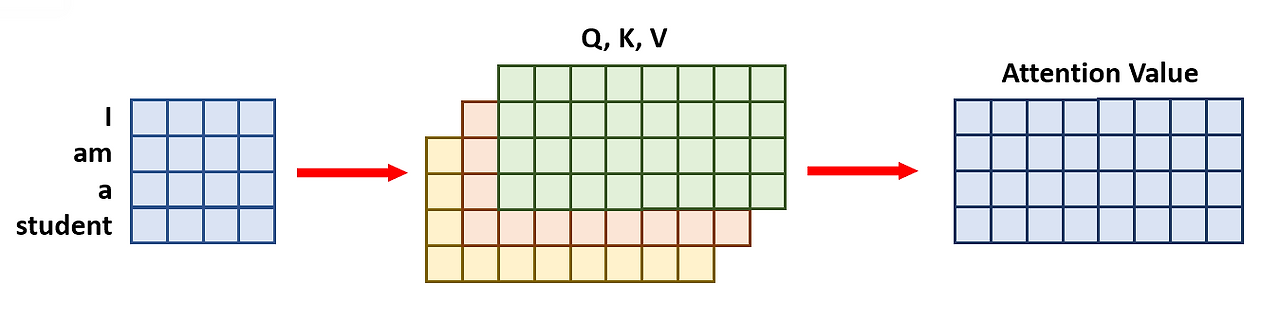
좀 더 간단한 문장을 통해 self attention이 수행되는 과정을 한번 보자. 실제로 attention이 수행될 때는 단어별로 계산되는 것이 아니라 문장 채로 들어가 병렬로 처리를 해주게 되어 'I am a student'라는 문장의 Q, K, V가 한꺼번에 구해진다. 이를 통해 attention을 수행하면 그림5의 오른쪽과 같이 attention score matrix가 도출되고 softmax( )*V 과정을 거쳐 attention value가 구해지게 된다. 이러한 작업은 encoder 뿐만 아니라 decoder에서도 수행되는데 decoder는 번역 대상이 되는 문장의 번역값 즉 답이기 때문에 완전한 문장 속에서 attention을 수행하기 어렵다. 이에 따라 masking 방식이 활용되는데 이는 1.4 Masked Multi-head Attention에서 좀 더 자세히 다루도록 하겠다.
1.3 Multi-head Attention

multi head attention은 attention을 병렬로 처리해주는 개념이라 생각하면 된다. Q, K, V를 head의 개수 만큼 나누어 주어진 문장에 대해 attention을 수행하고 나온 결과값들을 다시 합쳐주는 방식이다. 위 예시에서는 [4x8] 사이즈인 Q, K, V를 [4x2] 사이즈로 4개로 나누어 각각 attention value를 뽑아내고 마지막에 다시 합쳐주어 [4x8] 사이즈의 원래 크기의 attention vaule를 만들어 주고 있다. 그렇다면 이러한 multi-head attention은 왜 수행하는 것일까? 그 이유는 multi-head attention을 통해서 문장 내 단어관계를 다방면으로 살펴보면서 더욱 다양하고 정확한 의미를 추출할 수 있어 복잡한 문장을 다룰 때 더 유의미하기 때문이다. 아래의 예시를 보자.
I am a college student really like to play badminton and study artificial intelligence.
다음과 같은 문장에서 single-head attention을 사용하면 동사/형용사 라는 문법적인 부분에 초점을 맞춰 like, play, study와 같은 부분에 대한 유사도가 높게 책정될 수 있다.
I am a college student really like to play badminton and study artificial intellignence.
하지만 multi-head에서는 이전과 같은 문법적인 부분에서의 유사성 뿐만 아니라 내가 좋아하는 것이 배드민턴과 인공지능 이라는 문장 내의 관계를 포착하여 유사하다고 판단해 더욱 다양한 의미를 학습할 수 있는 것이다. 따라서 multi-head attention을 사용하면 문장 내 단어간의 종속성에 대해 다양하게 파악할 수 있고 더 복잡한 문장도 충분히 이해할 수 있을 뿐만 아니라 단어간 미묘한 관계까지 잘 잡아낼 수 있는 것이다.
1.4 Masked Multi-head Attention
Transformer는 학습을 할 때 Masked Multi-head Attention 방식을 사용한다. 이는 'I am a student'의 문장이 학습데이터로 주어지고 그에 대한 답으로 '나는 학생 입니다'의 문장이 주어졌을 때 순차적으로 다음 단어를 예측하는 방식(auto-regressive)을 보존하기 위해 사용된다. decoder 부분에서도 현재까지의 문맥을 파악하기 위해 sefl-attention이 사용되지만 아직 '나는'까지밖에 예측하지 않은 상황인데 정답으로 주어진 뒤의 단어 '학생', '입니다'에 attention을 취해 학습에 반영하게 되면 정답을 보고 학습을 하는 방식이 되어 제대로 된 성능을 나타낼 수가 없다. 따라서 decoder 내부에서 self-attention을 취하되 현재까지 예측한 단어들만을 토대로 self-attention을 취해 학습할 수 있도록 하는 것이다. 쉽게 말하면 모델이 '답을 외우는 방식'의 학습이 아니라 실제로 '다음 단어를 예측'하도록 하는 학습을 할 수 있도록 masking이 multi-head attention에 적용되는 것이다.

masked self attention은 그림9와 같은 방식으로 진행된다. decoder에서 정답으로 주어진 문장에 대해 selft attention을 수행하되 현재까지 나온 단어가 아닌 부분에 대해서는 -inf 값을 주어 활성화함수를 통과했을 때 값이 0에 근사하도록 만들어 주는 것이다. 이렇게 되면 현재까지 나온 값만을 토대로 다음 값을 예측할 수가 있다.
2. Positional Encoding
attention 방식에서는 문장 내 단어들의 선후 관계를 고려하지 못한다. I am a student라는 문장과 am I a student라는 문장의 의미는 완전히 다르다. 하지만 각 단어들의 문장 내 위치를 고려하지 못하는 attention은 두 문장을 동일하게 인식할 수 있다는 것이다. 따라서 단어들의 위치를 구분할 수 있도록 하는 장치가 필요한데 이것이 바로 Positional Encoding인 것이다.

Positional Encoding은 위와 같은 식을 통해 이루어진다. 먼저 pos는 말그대로 단어의 위치를 나타내는데 'I am student'라는 문장에서 I의 pos=0, am의 pos=1, student의 pos=2가 되는 것이다.
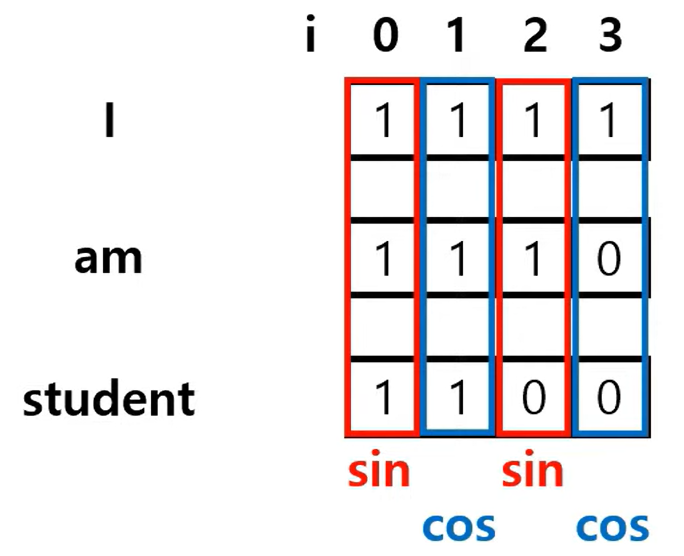
위 수식에서 i는 embodding vector의 위치를 의미한다. 예를들어 한 단어가 1x4의 embedding vector를 가질 때 첫번째 벡터는 i=0이 되고 두번째 벡터는 i=1이 되는 식이라는 것이다. 이때 짝수 벡터에 대해서는 sin 함수를, 홀수 벡터에 대해서는 cos 함수를 사용하는데 이와 같이 홀짝에 다른 함수를 사용하는 것은 경우의 수를 늘려 더 긴 문장에서도 좋은 성능을 보이기 위함이다.

문장의 길이가 길어져 embedding 벡터의 크기가 커지면 pos/10000^2i는 점차 0에 수렴해간다. 이에 따라 PE의 값은 0이나 1로 수렴하기 때문에 제대로 된 Positional Encoding이 이루어지기 힘들다. 따라서 2i를 d_model 값으로 나누어 더 긴 벡터들도 Positional Encoding이 이루어질 수 있도록 할 수 있다.
코디오페라 GOAT
https://codingopera.tistory.com/43
4-1. Transformer(Self Attention) [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼
codingopera.tistory.com
https://codingopera.tistory.com/44
4-2. Transformer(Multi-head Attention) [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼
codingopera.tistory.com
https://www.youtube.com/watch?v=-z2oBUZfL2o
https://www.blossominkyung.com/deeplearning/transformer-mha
트랜스포머(Transformer) 파헤치기—2. Multi-Head Attention
트랜스포머(Transformer) Attention is All You Need 중 Multi-head Attention에 대해 정리한 내용입니다.
www.blossominkyung.com