컴뷰터 비전분야의 대표적인 과제로는 Image Classification(이미지 분류), Localization, Object Detection(객체탐지), Semantic Segmentation(의미론적 분할), Instance Segmentation(객체분할)이 있다. Image classification은 이미지가 무엇을 나타내는지 분류하는 것으로 간단하다. Localization은 하나의 객체에 대해 bounding-box를 그림으로써 위치를 표현하는 작업이다. Object Detection은 여러 객체에 대해 Localization과 Classification을 모두 수행하는 것이라 할 수 있다. Segmentation은 bounding-box가 아닌 픽셀 단위로 Classification을 수행하는 문제로 Sementic Segmentation은 객체 각각을 구분하지 않고 동일 class일 경우 하나로 구분하는 것, instance segmentation은 동일 class의 서로 다른 객체들을 모두 구분하는 것을 의미한다. 각각의 과제들에 대해 한번 자세히 알아보도록 하자.
1. Classification
분류 모델은 입력된 이미지가 미리 정해둔 카테고리 중 어느 곳에 해당하는 지 구별하는 작업이다. 일반적으로 데이터 기반 방법(Data-Driven Approach)가 많이 쓰이는데 이는 이미지를 통해 모델을 학습시킨 뒤 분류작업을 수행하는 방식이다. 분류 모델들은 Object Detection이나 Segmentation 등 여러 작업들의 Backbone으로 이용되기도 한다.
발전사에 대해 간단하게 다뤄보자면 CNN과 같은 Deep Neural Network가 등장하기 이전에는 일반적인 머신러닝 기법들이 사용되었다. 이진 분류만 가능한 모델에는 로지스틱 회귀, 서포트 벡터 머신 classifier가 있고 다중 클래스 분류에서는 SGD, 랜덤 포레스트, 나이브 베이즈 classifier 같은 모델들이 사용되었다. 이진 분류기의 경우 여러개를 사용해 다중 클래스 분류에 활용되기도 하였다.
1998년 얀 르쿤 교수가 처음으로 CNN을 분류에 활용한 모델인 LeNet-5을 제안한 이후로 CNN은 줄곧 분류 문제에 활용되어 왔다. CNN을 활용한 분류에 있어서 초기의 패러다임은 "합성곱 층을 얼마나 깊게 쌓을 수 있느냐" 였다. 이 패러다임 하에서 분류 모델의 발전은 ILSVRC 대회가 주도한다. 아래 그림은 ILSVRC 우승 모델들을 2010년부터 에러율과 함께 나열해 놓은 것인데 2012년 AlexNet부터 쭉 CNN이 활용된 모델들이다. 해당 모델들의 합성곱 층을 중심으로 어떻게 발전해왔는지 한번 확인해보자.

LeNet-5(1998): 초기 CNN 분류 모델로 4개의 layer를 가지고 있다.
AlexNet(2012): 16.4%의 에러율로 2012 ILSVRC에서 우승한 모델이다. Lenet-5과 구조는 유사하지만 8개의 layer를 가진 조금 더 깊은 구조이다. GPU의 활용, ReLU, dropout, data augmentation(데이터 증강) 같이 지금은 아주 일반적으로 사용하는 것들이 이 모델에서 처음으로 사용되었다. 또한 LPN이라는 정규화 단계의 활용을 통해 더욱 다양한 특징을 학습할 수 있도록 하였다. 이를 통해 성능 개선이 1~2% 정도로 정체돼있던 상황에서 10% 이상의 성능 개선을 이끌어냈다.
ZFNet(2013): 11.7%의 에러율을 기록하며 2013 ILSVRC에서 우승한 모델이다. AlexNet의 각 layer를 시각화해 CNN 구조를 수정한 모델로 AlexNet과 같이 8개의 layer를 가졌다.
GoogLeNet(2014): 6.7%의 에러율을 기록하며 2014 ILSVRC 우승한 모델이다. "Inception"이라는 독특한 구조를 통해 22개의 layer를 가진 상당히 깊은 네트워크를 구성하면서도 AlexNet보다 10배나 적은 파라미터를 사용한다.
VGGNet(2014): 7.3%의 에러율로 2014 ILSVRC에서 준우승한 모델이지만 아주 단순한 구조로 GoogLeNet보다 더 많은 주목을 받았다. 16, 19개의 layer를 가지며 5x5의 filter를 사용한 이전 모델들과는 다르게 3x3 filter를 사용하고 padding을 처음으로 도입하면서 깊은 층을 쌓을 수 있게 됐다.
ResNet(2015): 3.6%의 에러율로 2015 ILSVRC에서 우승한 모델이다. 20층 이상에서부터는 layer를 깊게 쌓을수록 성능이 낮아지는 현상인 Degradation 문제가 발생했는데 Residual Learning이라는 개념을 도입해 152층까지 네트워크를 쌓은 모델이다. (단순한 발상 하나로 저렇게까지... 진짜 대단한 것 같다)
이후에 등장하는 GoogLeNet-v4(2016), SENet(2017)은 모두 GoogLeNet의 inception과 ResNet의 residual learning을 베이스로한 모델들이며 최종적으로 에러율이 인간의 절반 수준인 2.3%를 달성하며 Classification 모델의 눈부신 성장을 일궈낸 ILSVRC은 종료되었다.

ResNet(2016)의 등장 이후 다양한 변형모델들이 출현하였고 RNN과 강화학습을 활용한 NasNet(2018) 같은 새로운 모델도 두각을 보였다. 2019년 후반부터 EfficientNet(2019)이 등장하는데 이는 경량화를 위한 Conv구조인 MBConv을 사용하고 AutoML을 통해 depth, width, resolution의 최적의 조합을 찾아 구현한 모델이다. 이를 점차 개선하여 2020년 전후로 나온 모델들은 높은 정확도를 보이며 SOTA를 달성한 모습(NoisyStudent, Meta Psudo Labels 등)을 확인할 수 있다.
하지만 2021년 구글에서 "AN IMAGE IS WORTH 16x16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE"이라는 논문을 발표하면서 분류모델의 패러다임은 Transformer를 컴퓨터 비전에 활용하는 방향으로 바뀌게 된다. 이런 Transformer을 활용한 비전 모델을 VIT(Vision Transformer) 모델이라고 한다. single encoder, dual encoder, encoder-decoder 등을 활용한 여러 VTI 모델들이 등장했고 Convolution과 Transformer(Attention)이 합쳐진 CoAtNet(2022)과 같은 모델들도 등장했다. 위 그림의 출처에 들어가보면 VIT 등장 이후 현재까지 5개의 SOTA중 4개가 VIT를 활용한 모델인 것을 확인할 수 있다.
2. Object Detection

object detection은 위 사진과 같이 하나의 이미지에서 여러 물체를 분류하고 위치를 추정하는 작업이다. 이때 분류와 위치 추정 작업을 동시에 하느냐 구분해서 하느냐에 따라 1-satge object detecter, 2-satge object detecter로 나뉜다.
2-stage Object Detector

2-stage object dectector는 객체 후보지역들을 선정(region proposal) 한 이후 해당 지역들에 대한 classification이 이루어지는 구조이다. 객체 후보지역 선정 방식에는 selective search, RPN(Region Proposal Network)와 같은 기법들이 있는데 이들은 이미지 내 모든 영역들을 커버(탐색)하기 때문에 1-stage 방식보다 정확성이 높다. 하지만 많은 영역을 커버하는 만큼 많은 시간과 컴퓨팅 자원들이 소모된다. 따라서 자율주행과 같이 실시간으로 빠르게 객체를 탐지해야 하는 분야에서는 활용하기 어려운 방식이다.
1-stage Object Detector

1-stage object detector는 region proposal과 classification이 동시에 이루어지는 구조이다. 위 사진에서 보면 conv layer에서 특징 추출이 이루어진 뒤 특성 맵에서 각 grid or spatial location마다 바로 분류가 이루어진다고 나와있는데..... 사실 저대로는 직관적으로 이해가 잘 가지는 않을 것이다.
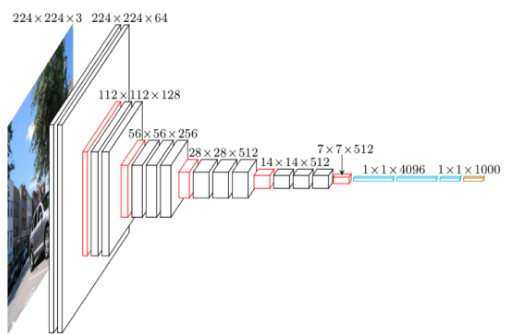

1-stage를 이해하려면 일단 backbone architecture를 확인해볼 필요가 있다. 좌측 그림을 보면 7x7x512 이후에 FC layer가 나온다. 이미지의 특징을 뽑아낸 뒤 FC layer에서 각 클래스 별로 속할 확률을 계산하여 분류 작업을 수행해주는 것이 일반적인 CNN 구조이다. 하지만 1-stage detector에서는 Convolutional layer를 거쳐 나온 이미지에 대한 풍부한 특징을 가진 7x7x512의 특성맵을 가지고 새로운 작업을 수행해 준다.

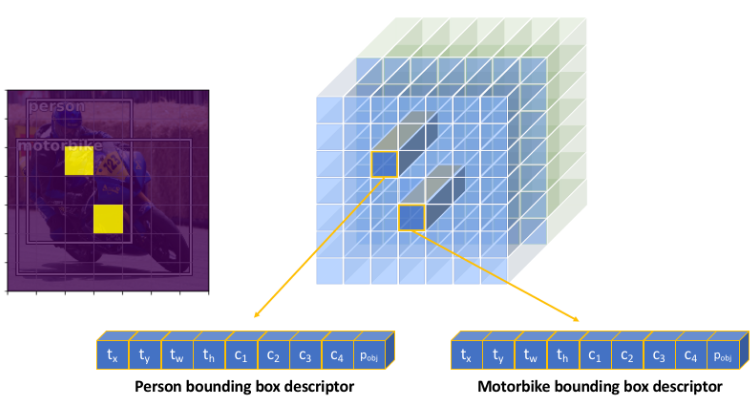
7x7x512는 자동차의 특징들을 추출한 feature map들이다. CNN은 대략적인 공간적 특징들은 보존하므로 원본 이미지를 7x7 grid로 나눈 것 중 대응하는 부분의 특징들을 feature map이 잡아낸다고 볼 수 있다. 그렇게 되면 원본 이미지에서 각 grid마다 특정 class에 대한 확률을 계산할 수 있다. 이때 각 grid마다 해당 grid를 중심으로 하는 bouding box에 대한 정보들도 포함하고 있다. 우측 그림에 보이는 사람과 오토바이의 bounding box와 같이 말이다. 따라서 각 grid마다 박스의 정보를 표현하는 t_x, t_y, t_w, t_h와 각 클래스에 속할 확률을 포함하는 c_1, c_2, c_3, c_4 그리고 물체가 있음을 감지하는 p_obj과 같은 정보가 포함되어 최종적으로 7x7x__과 같은 기존 CNN 구조에서와는 다른 텐서가 도출되는 것이다. 이는 특성 맵에서 각 grid마다 클래스에 속할 확률을 계산해주고 bounding box의 위치를 감지하여 최종적으로 각 grid별 위치정보와 분류 정보를 도출해내는 과정을 처리한다고 볼 수 있다. 앞선 2-stage는 지역을 추출한 이후 분류작업이 이루어지는 형태였으나 1-stage에서는 위와 같은 과정을 거쳐 나타나는 텐서를 통해 region proposal과 분류가 한꺼번에 이루어지는 것이다! 이와 같이 대부분의 1-stage object detector 모델들은 위치정보와 분류정보가 포함된 텐서를 한번에 도출한다. 특징을 추출하는 과정에서 차이가 있지만 말이다.
이러한 1-stage detector는 2-stage보다는 정확도가 낮지만 속도가 빠르기 때문에 real-time detection이 중요한 자율주행과 같은 분야에 적용되기 더 적합하다는 특징이 있다. 아래는 2-stage와 1-stage의 발전과정을 모델 별로 나타낸 표이다. 차례대로 공부해보면 좋을 듯 하다.

3. Segmentation
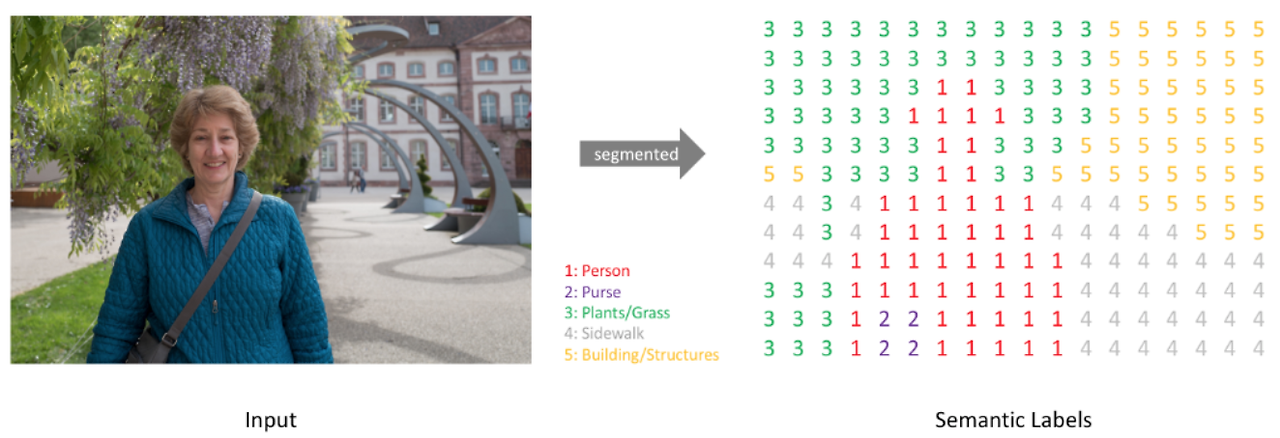
Classification이 이미지 전체에 대한 분류, Object Detection이 지역 단위 분류작업이었다면 Segmentation은 픽셀 단위 분류작업이다. 위 그림과 같이 이미지의 모든 픽셀을 지정된 class로 분류하는 작업인 것이다. segmentation은 각 pixel이 속하는 class만 구분하는 방식인 Semantic Segmentation과 같은 class라 하더라도 서로 다른 객체는 구분하는 Instance Segmentation 방식으로 구분된다. Semantic Segmentation의 대표적인 모델에는 FCN, SegNet, U-Net, DeepLab 등이 있고 Instance Segmenation에는 Mask RCNN, MMDetection, YOLACT 등이 있다.
Segmentation은 각각의 픽셀을 분류하는 작업이기 때문에 원본 이미지 내 각 사물들의 위치를 보존하는 특성맵이 필요하다. 하지만 CNN은 연산량 문제로 pooling layer가 필연적인데 여기를 통과할 때마다 이미지의 크기가 줄어들어 위치에 대한 세부적인 정보는 조금씩 잃게 된다. 심지어 네트워크 끄트머리의 FC layer를 통과하면 위치에 대한 정보는 아예 사라진다. 따라서 이러한 부분을 고려한 네트워크가 필요하다.
① Sliding Window

초기의 해결방법은 Sliding Window 방법이었다. 특정한 크기의 window가 전체 이미지를 한 픽셀 단위로 훑는데 각각의 window 만큼의 이미의 중앙 부분의 픽셀을 CNN에 집어넣어 분류 작업을 수행하는 것이다. 그렇게 되면 CNN을 통한 분류작업이 픽셀 수만큼 진행된다. 연산량이 어마어마하게 든다는 것이다.
② FC Layer -> Convolutional Layer
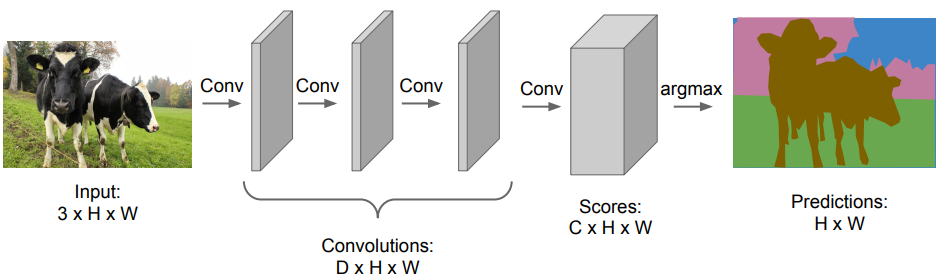

Sliding Window의 연산상의 문제와 위치보존의 문제를 해결하기 위해 FC layer를 C(클래스 수) x H(세로) x W(가로) 크기 만큼의 Convolutional layer로 대체하는 방법을 사용한다. FC layer는 고정된 크기의 이미지만 입력받을 수 있다는 취약점도 존재한다. 위 그림의 아래 그림을 보면 FC layer는 고양이를 분류하기 위해 고양이만큼 잘린 이미지를 사용할 수 밖에 없지만 FC를 Conv로 바꾼 구조에서는 이미지 크기에 구애받지 않는 것을 확인할 수 있다. 이는 연산량의 감소에도 큰 영향을 미치는데 이 부분에 대한 자세한 내용은 아래 첨부한 게시글에서 확인할 수 있다. Conv layer를 사용한 구조를 보면 해상도가 낮기는 하지만 고양이가 있을 가능성이 높은 지역에 heatmap 값들이 높게 표현된 것을 확인할 수 있다. 이처럼 FC를 Conv로 대체하면 연산량을 줄이면서도 원본 이미지 자체에서 위치정보를 어느정도 보존할 수 있는 것이다.
사실상 위 그림의 두 구조를 보면 다른 점이 있다. 아래 그림은 특성맵의 크기가 점차 작아지는데 위쪽 그림은 특성맵의 크기가 그대로다. 후자가 초기에 제시된 Conv layer를 사용한 구조인데 특성맵의 크기가 원본과 동일하기 때문에 각각의 픽셀의 위치 정보들이 그대로 보존된다. 위 그림의 아래쪽 그림에서 heatmap의 해상도가 낮은 것은 특성맵의 크기가 줄어들었기 때문인데 위쪽의 초기 구조에서는 특성맵의 크기가 원본과 동일하기 때문에 원본과 동일한 해상도를 지닌 채로 각각의 픽셀이 분류된다. 즉 원본의 픽셀 수 만큼 각각의 픽셀이 자신에 해당하는 이미지의 특징을 나타내는 것이다. 하지만 Conv net을 원본 이미지 크기를 그대로 밀고 나가며 계산하기 때문에 Sliding Window보다 계산량이 적다 해도 여전히 연산이 많은 부분이 있다.
FC layer를 Convolution layer로 대체하면 연산량이 감소하는 이유가 궁금하다면 아래 글을 확인하자.
https://calmdevstudy.tistory.com/5
Object Detection: 초기 Region Proposal 방식(Sliding Window, Selective Search)
Object detection을 수행하려면 객체가 존재할만한 지역의 후보군들을 추려내는 작업이 필요한데 이를 Region Proposal이라고 한다. 위 사진에서 2번과 같이 지역을 각각 나눠 하나씩 모델에 집어넣어 분
calmdevstudy.tistory.com
③ Encoder-Decoder 구조

이전의 구조는 원본 이미지의 크기를 유지하며 CNN을 통과시키기 대문에 연산량이 많이 들었다. 이에 대한 해결책으로 제시된 것이 Encoder - Decoder구조이다. 이는 특징을 추출할 때에는 크기를 줄이고 특징이 추출되면 이를 다시 자츰 원본의 크기로 늘려주는 방식이다. 전자를 donwsampling, 후자를 upsampling이라고 한다. donwsampling은 pooling, stride를 통해서 진행이 된다. 그렇다면 upsampling은 어떻게 진행될까?
Upsampling에는 unpooling, max unpooling, bilinear interpolation(선형보간법), Deconvolution 등 여러 방법들이 있지만 여기서는 transposed convolution(전치 합성곱)에 대해 알아보도록 하겠다.

우선 일반적인 합성곱 연산 과정을 확인해볼 필요가 있다. 상단 그림과 같이 실제 연산이 진행될 때는 kernel, input, output이 행렬로 표현된 뒤 계산이 진행된다. 3*3 kernel과 4*4 input의 연산을 통해 2*2 output이 도출된다고 하면 합성곱 연산은 아래와 같은 과정을 거쳐 이루어지는 것이다.
3*3 kernel -> 4*16 행렬로 변환
4*4 input -> 16*1 벡터로 변환
행렬 연산 후 4*1 벡터 도출
* 위 그림의 빈칸은 0으로 채워지는데 kernel의 크기 내에 포함되지 않는 input값들은 연산이 진행되지 않기 때문에 0으로 채워 넣는 것이라 할 수 있다.

Transposed convolution은 원본 이미지의 특징을 담고 있는 특성맵을 원본으로 되돌려놓는 작업이다. 따라서 4*1의 특성맵을 input으로 하여 16*1의 원본을 output으로 도출한다. 이때 합성곱 연산은 아래와 같은 과정을 거친다.
3*3 kernel -> 16*4 행렬로 변환
4*4 input -> 4*1 벡터로 변환
행렬 연산 후 16*1 벡터 도출
일반적인 convolution의 연산과 어떤 차이가 있는지 바로 눈치챘을 것이다. kernel의 행렬이 전치(transposed)되었다! 4*1 벡터과의 연산을 통해 16*1의 벡터를 도출해야 하므로 16개의 행과 4개의 열을 가진 행렬이 필요하고 이를 위해서는 기존 kernel를 전치시킬 필요가 있는 것이다. 연산 과정을 살펴보면 상단 좌측 그림에서 3*3 kernel이 2만큼 padding이 이루어진 특성맵에서 연산이 이루어질 때 kernel의 처음 위치에서의 연산이 전치행렬의 첫번째 행, kernel이 오른쪽으로 1px 이동했을 때의 연산이 두번째 행으로 쭉 대응되는 과정을 거쳐 4*4의 output이 도출된다. 위 그림에서는 가중치 w의 값들이 보존되고 위치만 전치되는 것으로 표현돼있지만 실제로는 학습을 통해 새로운 w의 값들을 찾아나가게 된다. 원본 이미지(output)과 특성맵(input) 값을 알고 있으니 학습 과정에서 특성맵을 원본으로 복원하기 위한 최적의 가중치를 찾아낼 수 있다.
<출처>
https://wikidocs.net/book/6651
https://velog.io/@qtly_u/Object-Detection-Architecture-1-or-2-stage-detector-%EC%B0%A8%EC%9D%B4
https://computing-jhson.tistory.com/58
https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
https://arxiv.org/pdf/1411.4038
https://hugrypiggykim.com/2019/09/29/upsampling-unpooling-deconvolution-transposed-convolution/
https://gaussian37.github.io/dl-concept-checkboard_artifact/
'Deep Learning > Computer Vision' 카테고리의 다른 글
| Object Detection: 초기 Region Proposal 방식(Sliding Window, Selective Search) (7) | 2024.04.15 |
|---|