요건 깃허브에 코드+설명 정리해놓은거
https://github.com/ksostel10/AI-X_DL_Project/blob/main/README.md
AI-X_DL_Project/README.md at main · ksostel10/AI-X_DL_Project
Contribute to ksostel10/AI-X_DL_Project development by creating an account on GitHub.
github.com
1. 어떤 데이터를 이용해야 하지?
데이터를 어떻게 구할 수 있을 지 고민하다 처음에 내놓은 답은 단순히 유튜브에서 축구경기 풀영상을 가져오는 것. 하지만 영상이 많지 않을 뿐더러 영상별로 길이가 다 달라 모델에 넣어주기 상당히 애매했다. 가장 긴 영상 길이 기준으로 패딩처리를 해야될 것으로 생각되지만 영상을 학습하는 과정에서 패딩 처리된 영상들은 그냥 아무것도 없는 화면이나 다름없기 때문에 모델의 성능저하에 큰 영향을 미칠 것으로 판단해 다른 데이터를 찾아보기로 했다.
구글링을 하던 와중 우리랑 유사한 프로젝트를 진행한 사람들이 SoccerNet이라는 사이트에서 축구 경기 영상 데이터를 활용한 것을 발견했고 SoccerNet의 데이터를 들여다본 결과 전후반 영상 길이가 각각 45분씩 모든 경기들이 똑같고 심지어 하이라이트 장면을 구분하기 좋게 골, 유효슈팅, 패널티킥 등 각종 상황마다 발생시간이 라벨링이 돼있는 json 파일까지 제공해줌을 확인할 수 있었다. 따라서 이 데이터를 사용하기로 결정했다.
https://www.soccer-net.org/data
SoccerNet - Data
Downloading our data
www.soccer-net.org
여기에 SoccerNet의 모듈을 사용해 각종 데이터를 다운받을 수 있는 코드를 정리해놨는데 우리는 여기서 Broadcast Videos, Action spotting labels 두 데이터를 활용했다. 해당 코드를 통해 데이터를 다운받으면 아래와 같은 파일이 생성된다.


json 파일은 이렇게 구성돼있는데 우리는 label이 Goal, Penalty, Shots on target(유효슈팅), Shots off target(유효슈팅이 아닌 슈팅) 네 상황을 하이라이트 장면이라 정하고 이들에 해당되는 영상들을 학습 데이터로 활용하기로 결정했다.
2. 학습 데이터를 어떻게 구성하지?
다음의 문제는 학습데이터를 구성하는 방법이었다. 일반적으로 하이라이트 장면에서는 골장면이라고 하면 해당 골장면이 나오기까지의 빌드업 과정도 포함된다. 위 json 파일에 지정된 시간대를 직접 확인해본 결과 골장면이라고 라벨링된 시간대는 정확히 골이 들어가는 시간대를 기준으로 설정돼있었다. 따라서 "골이 들어가기까지의 빌드업 과정 + 다음장면의 자연스러운 연결을 위한 골 이후의 상황"을 고려해 골장면 이전 10초 + 이후 5초를 추가해 라벨링된 시간대 기준으로 -10~+5초 즉 15초간의 영상을 학습 데이터로 구성하기로 했다.
여기에 이전에 오디오 데이터를 다뤄본 적 있는 팀원이 하이라이트 부분 때 해설자+관중들의 소리가 커지는 것을 보고 오디오 데이터도 학습에 활용하는 방법을 제안해 영상+오디오 데이터를 모두 활용하는 방향으로 학습을 진행하기로 하였다.
이때 영상 추출과 오디오 추출은 ffmpeg-python 모듈을 이용했다. ffmpeg는 원래 쉘에서 실행되는 명령어이기 때문에 외부부 명령어를 실행시킬 수 있는 subprocess 모듈을 활용해 파이썬 코드만으로 실행될 수 있도록 하였다. 근데 찾아보니 ffmpeg-python 모듈로는 subprocess 없이 파이썬만으로 충분히 실행될 수 있었던 것 같다. 오디오추출은 먼저 영상데이터부터 추출하고 추출된 영상데이터에서 오디오를 따로 추출할 수 있도록 하였다.
def ffmpeg_extract_subclip_accurate(input_path, start_time, end_time, output_path):
command = [
"ffmpeg",
"-y", # 기존 파일 덮어쓰기
"-i", input_path, # 입력 파일
"-ss", str(start_time), # 시작 시간
"-to", str(end_time), # 종료 시간
"-c:v", "libx264", # 비디오 코덱: H.264 (효율적이고 호환성 높음)
"-preset", "fast", # 인코딩 속도와 품질의 균형 (fast 추천)
"-crf", "23", # 비디오 품질 설정 (낮을수록 고품질, 23은 적절한 기본값)
"-c:a", "aac", # 오디오 코덱: AAC (효율적이고 품질 유지)
"-b:a", "128k", # 오디오 비트레이트 (128 kbps는 일반적인 설정)
"-strict", "experimental", # AAC 관련 호환성
output_path
]
subprocess.run(command, check=True)
영상추출하는 코드를 보면 인코딩관련 옵션이 비디오는 "-c:v", "libx264" 오디오는 "-c:a", "aac"라 돼있는 것을 확인할 수 있다. 처음에는 "-c", "copy"만으로 추출을 하였는데 한창 오디오 데이터를 모델에 넣으려고 하는데 계속 텐서가 0으로 나오는 부분이 나와서 한참을 고민하다 해당 오디오 파일을 열어봤더니 소리가 아예 나오지가 않았었다. 그 오디오 파일에 해당하는 비디오 파일에서도 영상은 나오는데 소리는 따로 나오지 않아서 gpt와 구글링을 통해 찾아보니 "-c", "copy" 옵션이 문제였음을 확인할 수 있었다. 이 옵션은 코덱(인코딩, 디코딩 하는 주체)을 사용하지 않고 원본을 그대로 복사하는데 그러다보니 오디오 부분에서 데이터 손실이 발생하였던 것 같다. 이를 "-c:v", "libx264" 과 "-c:a", "aac" 같이 비디오, 오디오를 디코딩, 인코딩하는 코덱을 따로 지정하여 해결할 수 있었다.
https://dongle94.github.io/cv/ffmpeg-python-module/
[ffmpeg] FFMPEG Python library
ffmpeg를 python 언어에서 다루기
dongle94.github.io
https://m.blog.naver.com/jin696/100078863430
코덱(Codec)그리고 인코딩/디코딩 설명
코덱(CODEC)이란 동영상을 압축(COmpressor)하거나 해제(DECompressor) 할 수 있는 프로그램을 ...
blog.naver.com
3. 데이터를 어떻게 학습시키고 모델은 어떻게 설계해야 될까?
비디오 데이터
우선 비디오 데이터를 학습하기 위해서는 15초간의 학습 데이터 영상에서 일부 프레임을 추출해 각 시점의 특징을 뽑아낸 뒤 해당 특징들을 시간에 따라 학습할 수 있도록 해야 했다. 일단 우리가 활용한 영상이 25fps(초당 25프레임)이였기 때문에 초당 5프레임씩 추출해 하나의 영상당 75개의 프레임을 통해 학습을 진행할 수 있도록 하였다. 또 원본영상의 height, width가 224x398이었기 때문에 224x224로 resizing 해주어 (25*15, 3, 224, 398)이었던 raw video data를 (5*15, 3, 224, 224)로 맞춰주었다. 이 75개의 프레임의 각각의 특징을 추출하기 위한 모델로는 처음에 VIT를 활용하려 했지만 기껏해야 로컬 or 코랩에서 돌리는 환경 대비 모델의 크기가 너무 커서 resnet을 활용해 특징을 추출하기로 했다. 이때 ImageNet -1K Pretrained Model을 사용해 해당 resnet 모델을 통과한 데이터의 크기는 (75, 1000)이 된다. 이후 시간축에 따라 학습하도록 하는 모델은 LSTM보다 학습속도가 빠른 GRU를 사용하였다. 이때 hidden size를 512로 사용하고 bidirectional 옵션을 True로 지정했기 때문에 output은 (512*2)가 되고 이를 linear layer에 통과시켜 크기를 512로 만들어주었다. 여기에 layernorm, relu, dropout을 적용하면 비디오 데이터 특징을 담은 텐서가 준비된다!
오디오 데이터
self.mel_spectrogram = MelSpectrogram(
sample_rate=48000, n_fft=400, hop_length=160, n_mels=n_mels
)
오디오 데이터는 그대로 학습할 수 없기 때문에 먼저 mel spectrogram 변환을 활용해 sequence 데이터로 바꿔줄 수 있도록 하였다. 그리고 하이라이트 장면에서는 소리가 확연히 커지기 때문에 mel spectrogram을 주파수가 아닌 데시벨 기준으로 바꿔주었다. 위 코드에서 보면 mel spectrogram으로 바꿔줄 때 초당 sample_rate를 48,000(48hz)로 맞춰주었다. 그럼 총 15초 영상에서 48,000*15 = 720,000 개의 샘플이 추출되고 여기서 오디오 신호(샘플) 400(n_fft)개씩, 160(hop_length)개의 간격으로 추출하여 하나씩 데이터를 만들어 주었다.
https://velog.io/@eunjnnn/Understanding-the-Mel-Spectrogram
Understanding the Mel Spectrogram
다음 블로그를 번역했습니다.signal은 시간이 지남에 따라 특정 양의 변화입니다. Audio의 경우 변화하는 양은 기압(air pressure)입니다. 이 정보를 디지털 방식(digitally)으로 캡처하려면 어떻게 해야
velog.io
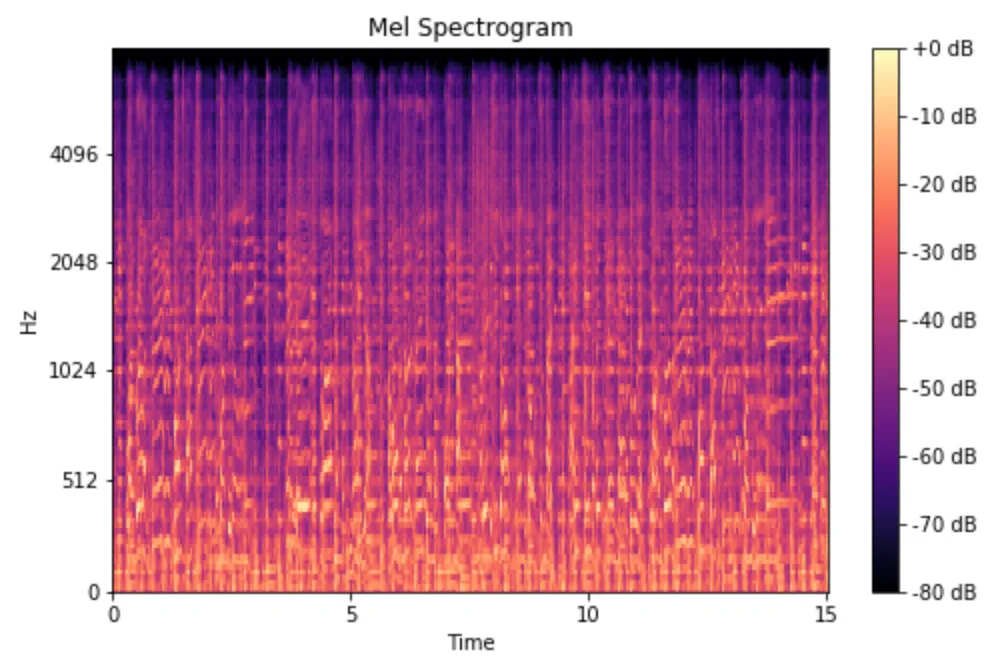
예를 들면 위 사진에서 15초간의 오디오 신호는 총 720,000개의 신호로 이루어져 있고 여기서 앞에서부터 신호 400개를 추출해 하나의 데이터를 구성하고 160만큼 이동한 뒤 다시 신호 400개를 추출하여 또 다른 데이터를 구성하게 된다. 그렇게 하면 대략 4500개의 데이터가 도출된다. 이때 시간의 흐름에 따라 조금씩 이동하며 데이터를 추출했기 때문에 이는 sequence 데이터가 된다. 이때 400만큼의 신호는 1x64로 표현되는데 400개의 오디오 신호를 주파수 대역별로만 나눠 한번에 표현해놓은 것으로 이해하면 된다. 이때 위 그림에 db이 있는건 주파수 대역별 db크기를 나타낸 것이므로 이를 통해 sequence 데이터를 추출한다면 400개의 오디오 신호에서 주파수 대역별로 db크기를 합쳐놓은 것으로 이해하면 되겠다. 이렇게 되면 하나의 오디오 파일이 (1, 64, 4500) = (channel, freq, time)의 텐서로 변환된다.
class ConvStridePoolSubsampling(torch.nn.Module):
def __init__(self, conv_channels=32):
super(ConvStridePoolSubsampling, self).__init__()
self.conv_block = torch.nn.Sequential(
# Conv Layer 1 (1, 1, 64, 4500)
torch.nn.Conv2d(1, conv_channels, kernel_size=3, stride=2, padding=1), # (1, 64, 4500) -> (32, 32, 2250)
torch.nn.BatchNorm2d(conv_channels),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)), # (32, 32, 2250) -> (32, 16, 1125)
# Conv Layer 2x
torch.nn.Conv2d(conv_channels, conv_channels * 2, kernel_size=3, stride=2, padding=1), # (64, 16, 1125) -> (64, 8, 563)
torch.nn.BatchNorm2d(conv_channels * 2),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)), # (64, 8, 564) -> (64, 4, 281)
# Conv Layer 3
torch.nn.Conv2d(conv_channels * 2, conv_channels * 4, kernel_size=3, stride=2, padding=1), # (64, 4, 281) -> (128, 2, 141)
torch.nn.BatchNorm2d(conv_channels * 4),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 1), stride=(2, 1)), # (128, 2, 141) -> (128, 2, 70)
# Conv Layer 4
torch.nn.Conv2d(conv_channels * 4, 256, kernel_size=3, stride=(2, 2), padding=1), # (128, 2, 70) -> (256, 1, 35)
torch.nn.BatchNorm2d(256),
torch.nn.ReLU(),
)
def forward(self, x):
x = self.conv_block(x)
batch_size, feautres, channel, time = x.size() # (1, 256, 1, 35)
x = x.view(batch_size, time, -1) #(1, 35, 256) : (batch, time, features)
return x
하지만 이렇게 나온 텐서를 바로 학습시키기엔 크기가 너무 크다. 그래서 합성곱 신경망을 통해 downsampling을 하는 작업을 진행해주었다. 이렇게 되면 크기가 (1, 64, 3400) 이었던 오디오 텐서를 (1, 35, 256) 사이즈로 줄이면서 특징까지 뽑아낼 수 있다. 코드 오른쪽 주석을 보면 크기가 어떻게 줄어드는지 확인할 수 있다. 이렇게 크기까지 줄어든 오디오 데이터의 텐서를 GRU 모델에 넣어준 뒤 layer norm, relu, dropout을 적용해주면 오디오 데이터의 시간적 특징을 뽑아낸 텐서들이 준비된다!
데이터 합치기
우리는 비디오 데이터와 오디오 데이터를 모두 활용해 학습을 하이라이트를 판별하기로 하였기 때문에 각각 다른 모델을 통과해 비디오, 오디오의 특징을 각각 담은 텐서를 합친 뒤 fc layer와 softmax를 통과시켜 최종 하이라이트 확률을 도출할 수 있도록 하였다. 이진분류임에도 softmax를 사용한 이유는 sigmoid를 사용했을 때 성능이 훨씬 더 안좋게 나왔고 그 이유를 확인하기 어려워 softmax를 사용하였다.
전체적인 모델의 구조와 코드는 아래와 같다
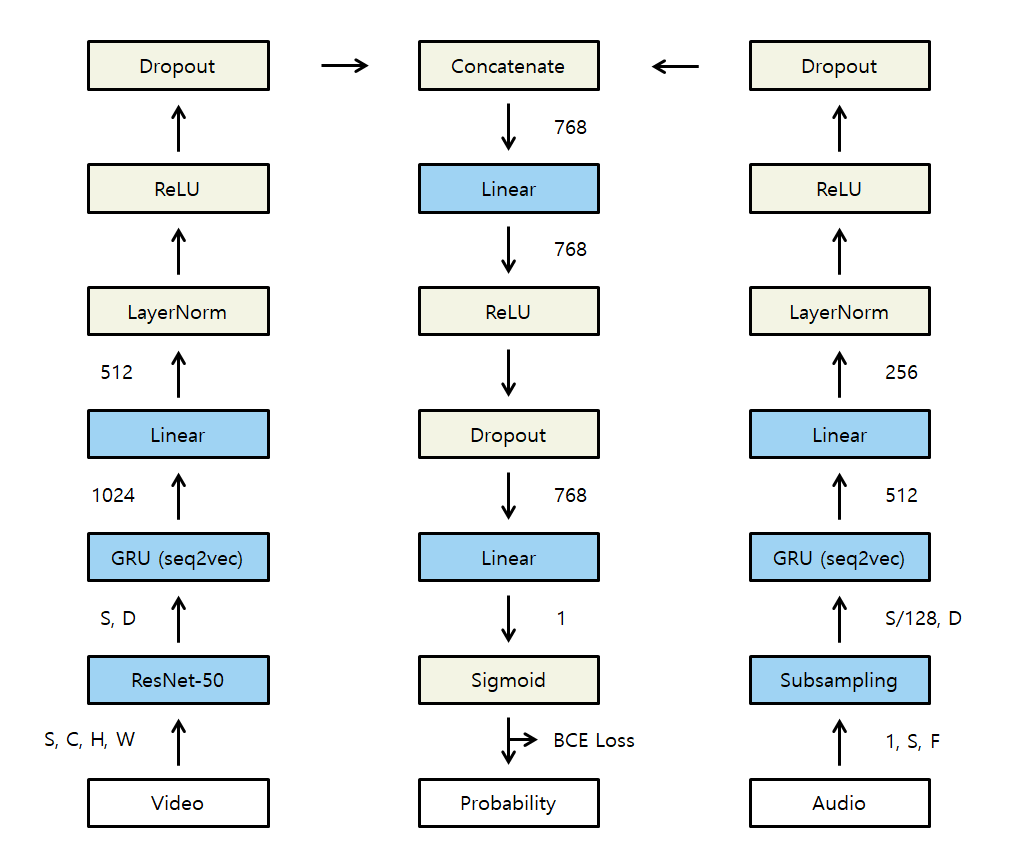
class HighlightsClassifier(torch.nn.Module):
def __init__(self):
super(HighlightsClassifier, self).__init__()
self.ConvStridePoolSubsampling = ConvStridePoolSubsampling()
self.Seq2VecGRU_Video = Seq2VecGRU_Video()
self.Seq2VecGRU_Audio = Seq2VecGRU_Audio()
self.resnet = resnet50(weights=ResNet50_Weights.DEFAULT)
self.fc1 = torch.nn.Linear(768, 768)
self.fc2 = torch.nn.Linear(768, 2)
self.audio_norm = torch.nn.LayerNorm(256)
self.video_norm = torch.nn.LayerNorm(512)
self.relu = torch.nn.ReLU()
self.dropout_audio = torch.nn.Dropout(p=0.2) # 오디오 경로 dropout
self.dropout_video = torch.nn.Dropout(p=0.2) # 비디오 경로 dropout
self.dropout_fc = torch.nn.Dropout(p=0.3) # Fully Connected Layer dropout
def forward(self, x1, x2):
# 오디오 경로 처리
x1 = self.ConvStridePoolSubsampling(x1)
x1 = self.Seq2VecGRU_Audio(x1)
x1 = self.audio_norm(x1) # LayerNorm 적용
x1 = self.relu(x1) # ReLU 적용
x1 = self.dropout_audio(x1) # Dropout 적용
# 비디오 경로 처리
num_frames, channels, height, width = x2.shape
batch_size = num_frames // 75
x2 = self.resnet(x2)
x2 = x2.view(batch_size, num_frames // batch_size, -1) # Reshape for GRU: (batch_size, num_frames, feature_size)
x2 = self.Seq2VecGRU_Video(x2)
x2 = self.video_norm(x2) # LayerNorm 적용
x2 = self.relu(x2) # ReLU 적용
x2 = self.dropout_video(x2) # Dropout 적용
# 두 경로 결합
x3 = torch.cat((x1, x2), dim=1)
# Fully Connected Layers
x3 = self.fc1(x3)
x3 = self.relu(x3) # ReLU
x3 = self.dropout_fc(x3) # Dropout 적용
x3 = self.fc2(x3)
x3 = torch.softmax(x3, dim=1)
return x3
이렇게 준비된 모델에 준비된 데이터를 넣고 학습을 시키면 highlights classifiers 모델 완성이다!
4. 준비된 highlights classifiers 모델로 영상을 어떻게 추출할 수 있을까?

이 부분에선 크게 좋은 방식이 떠오르진 않아 다소 무식한 방법을 사용했다. 우선 새로 주어진 45분 비디오 풀영상 전체를 텐서로 바꿔놓고 비디오 풀영상을 오디오로 변환시킨 뒤 mel spectrogram을 적용하고 텐서로 바꿔놓았다. 이후 오디오, 비디오 텐서에서 처음부터 각각 15초 정도에 해당하는 추출하고 모델에 넣어 도출된 확률이 임계치를 넘었을 때 해당 시간대(시작, 종료시간)을 highlights 리스트 변수에 넣어놓았다. 이때 연속적으로 하이라이트 장면이 더 이어질 수도 있으므로 3초 뒤의 지점부터 다시 15초간 추출해 모델에 넣어 도출된 확률이 임계치를 넘으면 기존의 리스트에 저장된 종료시간에서 3초를 더해준 값으로 갱신하는 방식으로 하이라이트 시간대를 추출했다. 이 작업을 지속적으로 하면 우리의 highlights classifier 모델이 판별한 하이라이트 장면들의 시간대가 리스트에 쭉 담기게 되고 이 리스트에 저장된 값들을 토대로 기존의 풀영상에서 하이라이트 영상을 추출해내면 된다! 코드는 깃허브에 extract_highlights.py 파일을 확인하자.
5. 한계점
처음에 학습 데이터의 길이를 15초로 설정한게 미스였다. 실제 골장면은 1~2초정도에 그치는 반면 빌드업 장면, 세레머니 때문에 클로즈업 되는 장면이 나머지 13~14초를 차지한다. 패스하며 빌드업하는 장면은 전체 학습 데이터 길이중에 상당부분을 차지하여 더 중점적으로 학습되고 세레머니때문에 클로즈업되는 장면은 학습데이터 대부분이 멀리에서 촬영되는 장면인것 과는 확연히 차이가 나는 장면이기 때문에 더 치중되어 학습되어 오히려 하이라이트라고 판별한장면이 골/유효슈팅장면보다 패스를 돌리는 장면, 별 상황이 아닌데도 선수들이 클로즈업 돼있는 장면들이 더 많았던 것 같다.
차라리 슈팅장면 전후 2~3초로 짧게 학습데이터를 구성하여 학습시킨 뒤 하이라이트라고 판별된 장면에서 앞으로 8초 뒤로 4~5초가량을 덧붙여 추출하는 방식이 하이라이트 장면 탐지를 더 잘할 수 있지 않았을까 하는 아쉬움이 남는다.